Optimiser les performances de MySQL en 4 étapes
MySQL s’installe en une commande sous Linux et il est tout de suite prêt à l’utilisation sans avoir à se soucier des performances. Généralement on ne se pose pas trop de questions au démarrage… on laisse la conf par défaut et ont démarre les développements de notre application web…
Cependant, est-ce que la conf par défaut est vraiment adaptée à notre site ? Est-ce que la conception de notre base de données est cohérente ? Est-ce que les ralentissements que vous observez indiquent que le serveur doit être gonflé, un problème dans la configuration ou un problème au niveau des requêtes et des applications qui sollicitent la base ?
Cet article vous apporte 4 pistes d’exploration pour comprendre le fonctionnement de MySQL et optimiser sa configuration.
- Etat des lieux général avant de démarrer
- Vérification de la configuration
- Analyse des requêtes longues
- Analyse des usages
1. État des lieux général avant de démarrer
Avant de démarrer, il est nécessaire de faire un état des lieux général tout simplement pour savoir où l’on met les pieds.
Vérification de l’espace disque
Vérifions, par précaution, l’espace disque sur le serveur. C’est assez basic, mais il arrive très souvent que l’espace disque soit trop « juste »… et dans ce cas, il faut corriger le problème avant de poursuivre toute autre investigation.
Allons voir dans la conf, les répertoires utilisés par MySQL:
[code lang= »bash »] cat /etc/mysql/my.cnf | grep dir basedir = /usr datadir = /var/lib/mysql tmpdir = /tmp [/code]Vérifiez ensuite l’espace libre sur le disque:
[code lang= »bash »] df -h Filesystem Size Used Avail Use% Mounted on rootfs 613M 278M 304M 48% / tmpfs 1.2G 236K 1.2G 1% /run tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 2.4G 0 2.4G 0% /run/shm /dev/sda1 228M 20M 197M 10% /boot /dev/xxxx-home 1.6G 1.3G 256M 84% /home /dev/xxxx-tmp 124M 5.6M 113M 5% /tmp <= !!! /dev/xxxx-usr 1.7G 1.2G 346M 78% /usr /dev/xxxx-var 2.8G 2.0G 672M 76% /var <= !!! [/code]Ici, par exemple, on voit que la partition /var qui héberge les données (cf datadir=/var/lib/mysql) n’a que 672M d’espace libre. C’est peu… même si, dans notre cas, la base tourne bien aujourd’hui, il est très probable que l’on remplisse rapidement cette partition. D’autant plus que cette partition héberge également les sources des applications web ainsi que les différents logs (avec une configuration standard).
Deuxième problème, la partition /tmp qui est utilisée temporairement par MySQL (cf tmpdir=/tmp) est également trop petite et devrait être augmentée.
Avant de démarrer toute autre investigation, commencer par vérifier l’espace disque utilisé et disponible sur votre serveur. On peut facilement se retrouver complètement bloqué (voire perdre des données) si on commence à faire des dumps, manipuler la configuration ou jouer avec les logs sur un serveur qui est limite en espace libre.
Dimensionnement de la base de données
Deuxième étape, jetons un coup d’oeil à l’espace occupé par la base de données:
[code lang= »sql »] SELECT table_schema, engine, SUM(DATA_LENGTH)/(1024*1024) AS "Data (Mo)", SUM(INDEX_LENGTH)/(1024*1024) AS "Indexes (Mo)" FROM information_schema.tables GROUP BY table_schema, engine; [/code] [code lang= »bash »] +——————–+——————–+———–+————–+ | table_schema | engine | Data (Mo) | Indexes (Mo) | +——————–+——————–+———–+————–+ | cdansmaliste | InnoDB | 824.8594 | 213.6563 | <= !!! | information_schema | MEMORY | 0.0000 | 0.0000 | | information_schema | MyISAM | 0.0000 | 0.0088 | | mysql | CSV | 0.0000 | 0.0000 | | mysql | MyISAM | 0.5783 | 0.0957 | | performance_schema | PERFORMANCE_SCHEMA | 0.0000 | 0.0000 | +——————–+——————–+———–+————–+ [/code]cdansmaliste est la base qui va me servir de support tout au long de cet article. On voit ici qu’elle occupe 824Mo de données plus 213Mo d’index.
Il peut être intéressant de relever quelques métriques complémentaires sur cette base avant de poursuivre:
[code lang= »sql »] SELECT table_name, engine, table_rows, avg_row_length, data_length/(1024*1024) AS ‘data_length (Mo)’, index_length/(1024*1024) AS ‘index_length (Mo)’, create_options FROM information_schema.tables WHERE table_schema=’cdansmaliste’; [/code] [code lang= »bash »] +————+——–+————+—————-+——————+——————-+—————-+ | table_name | engine | table_rows | avg_row_length | data_length (Mo) | index_length (Mo) | create_options | +————+——–+————+—————-+——————+——————-+—————-+ | friend | InnoDB | 5581726 | 62 | 334.8281 | 157.2813 | | | item | InnoDB | 957865 | 513 | 468.9531 | 47.3750 | | | theme | InnoDB | 3 | 5461 | 0.0156 | 0.0156 | | | user | InnoDB | 10199 | 155 | 1.5156 | 0.4219 | | | wishlist | InnoDB | 54789 | 374 | 19.5469 | 8.5625 | | +————+——–+————+—————-+——————+——————-+—————-+ [/code]On en extrait, entre autres, les informations suivantes:
- Toutes les tables sont en InnoDB
- La table avec le plus de lignes est « friend » qui comporte plus de 5 millions d’enregistrements.
- La table la plus volumineuse est « item » avec 468Mo de données
- Aucune table n’est partitionnée (cela apparaîtrait dans « create_options »)
Configuration de base d’InnoDB
On va ensuite chercher des informations sur la manière dont InnoDB est configuré pour fonctionner.
[code lang= »sql »] SHOW VARIABLES LIKE ‘innodb_data%’; SHOW VARIABLES LIKE ‘innodb_file%’; SHOW VARIABLES LIKE ‘innodb_log%’; [/code] [code lang= »bash »] +—————————+————————+ | Variable_name | Value | +—————————+————————+ | innodb_data_file_path | ibdata1:10M:autoextend | <= (1) | innodb_file_format | Antelope | | innodb_file_format_check | ON | | innodb_file_format_max | Antelope | | innodb_file_per_table | OFF | <= (2) | innodb_log_buffer_size | 8388608 | | innodb_log_file_size | 5242880 | <= (3) | innodb_log_files_in_group | 2 | <= (4) | innodb_log_group_home_dir | ./ | +—————————+————————+ [/code]Voila ce que nous dit cette config:
- Les données sont stockées dans un seul fichier (2) dans le tablespace system
- Le tablespace system est stocké dans le fichier ibdata1 qui a une taille initiale de 10M. Ce fichier va grossir en fonction des besoins (cf autoextend), mais il n’y aura toujours qu’un seul fichier (1)
- Les fichiers de logs binaires (qui permettent entre autres les recovery) sont configurés pour qu’il y ait 2 fichiers (4) de 5Mo (3)
En observant le dossier /var/lib/mysql, on retrouve effectivement ces informations:
[code lang= »bash »] ls -lh drwx—— 2 mysql mysql 4,0K mars 22 11:24 cdansmaliste -rw-rw—- 1 mysql mysql 1,2G mars 22 20:51 ibdata1 <= (1) -rw-rw—- 1 mysql mysql 5,0M mars 22 20:51 ib_logfile0 <= (3 et 4) -rw-rw—- 1 mysql mysql 5,0M mars 22 20:44 ib_logfile1 <= (3 et 4) drwx—— 2 mysql root 4,0K mars 22 11:22 mysql -rw——- 1 root root 6 mars 22 11:22 mysql_upgrade_info drwx—— 2 mysql mysql 4,0K mars 22 11:22 performance_schema [/code]Vérification des tables corrompues
Dernière étape de ce premier point, vérifiez que les tables ne soient pas corrompues:
Cette opération met un verrou en lecture sur chaque table avant d’effectuer l’opération de vérification des données. Cela peut ralentir ou bloquer temporairement d’autres utilisateurs qui tenteraient d’accéder aux tables.
De plus, avant d’exécuter cette commande, assurez-vous d’avoir fait une sauvegarde de la base de données.
Avant de démarrer, commencez par faire un état des lieux de la situation: espace disque, taille de la base et des tables, éléments de base de la configuration et vérification des tables corrompues. Cela vous évitera des ennuies et vous donnera des indices pour la suite.
2. Vérification de la configuration
Dans la mesure où l’objet de cet article est de vous orienter rapidement vers des pistes d’amélioration des performances, nous allons installer un outil qui va nous faciliter le travail. Cet outil analyse la configuration en la comparant aux résultats et aux performances (utilisation du cache, des buffers, …) obtenues depuis le démarrage du serveur.
MySQL Tuner
L’outil que nous allons utiliser est MySQL Tuner. C’est un outil qui va analyser la configuration et les status de MySQL pour émettre des préconisations. MySQL Tuner est en read-only uniquement (il ne modifie pas pour vous la configuration).
L’analyse de MYSQL Tuner ne sera pertinente que si le serveur tourne déjà depuis plusieurs jours en conditions réelles et normales d’utilisation.
Pour l’installer et l’exécuter:
[code lang= »bash »] wget https://raw.githubusercontent.com/major/MySQLTuner-perl/master/mysqltuner.pl perl mysqltuner.pl [/code]MySQL Tuner génère, dans notre exemple, l’analyse suivante:

Il contrôle tout d’abord les logs et nous indique qu’il a trouvé 7 warnings et 4 erreurs. Il est conseillé d’aller jeter un coup d’oeil dans les logs pour vérifier de quoi il s’agit.
Si le fichier de log était trop volumineux, l’outil nous l’indiquerait également.

MySQL Tuner fait ensuite une vérification des type de moteurs de table installés. Il confirme les informations trouvées au premier point concernant la taille du fichier data InnoDB.
L’outil analyse les tables pour détecter si des tables sont fragmentées. Cela peut être le cas, si de nombreuses opérations de suppression de lignes ont eues lieu. Une des conséquences des tables fragmentées sont un espace disque non optimisé et des temps de réponse plus long sur certains types de requêtes (fullscan par exemple). Si des tables fragmentées sont détectées, reportez-vous à la documentation pour les défragmenter. Une technique consiste à effectuer une opération d’altération « à blanc » sur une table, par exemple (s’il s’agit d’une table InnoDB):
MySQL Tuner va ensuite analyser quelques paramètres liés à la performance:

Ce bloc contient beaucoup d’informations utiles. Entre autres:
- Sur les requêtes effectuées: 77% sont des lectures contre 23% d’écritures
- La mémoire sur le serveur est de 2G, MySQL est configuré pour n’en consommer que 597Mo. Depuis le démarrage, MySQL n’a consommé que 208Mo sur 597Mo qui lui sont alloué. Cela ne représente que 10% de la RAM installée.
- On voit également que le serveur n’était pas vraiment très sollicité par d’autres processus depuis le démarrage, seul un maximum de 99Mo a été utilisé par d’autres processus depuis le démarrage. Il s’agit effectivement d’un serveur de test mis en place spécialement pour la rédaction de cet article. Sur votre environnement, il faut vous attendre à une consommation plus importante des autres processus.
- Vous aurez également une indication du nombre de requêtes lentes. Ici, j’ai volontairement configuré mon serveur pour qu’il log toutes les requêtes comme lentes (nous verrons ce point plus loin)
- Seul 3% des connections de clients possibles ont été consommées.
- Le cache n’a pas semblé être très efficace dans notre cas. Seul 176 requêtes ont été servies via le cache sur 39000 requêtes.
- 74% des opérations de tri ont nécessitées l’utilisation de tables temporaires
- Aucune jointure n’a été effectuée sans utiliser d’index
- MySQL utilise des tables temporaires en mémoire pour traiter certaines requêtes (cf la doc). Dans notre cas, 59% des tables temporaires ont dues être écrites sur disque. Cela indique la nécessité d’augmenter les paramètres tmp_table_size et max_heap_table_size. Il faudra également se poser la question plus tard de l’usage et des requêtes qui sont effectuées car des requêtes non optimisées peuvent également être la cause de cette utilisation des tables temporaires.

MySQL Tuner analyse l’utilisation du key buffer pour les types de tables MyISAM. Mes données de test ne sont qu’en InnoDB, ces résultats ne sont pas représentatifs.
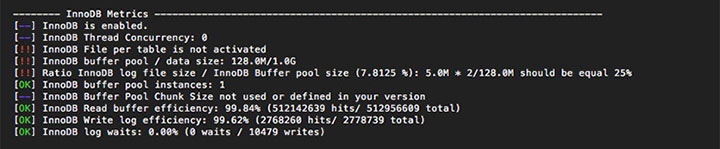
MySQL Tuner analyse la configuration et l’usage d’InnoDB.
- Comme nous l’avons vu plus haut, « file_per_table » est désactivez et les données sont donc stockées dans le table space system.
- L’InnoDB Buffer Pool est un espace mémoire dans lequel MySQL stocke des données et des index en cache. Dans notre exemple, la taille du buffer pool est de 128Mo. Il est conseillé d’avoir un buffer pool le plus gros possible tout en laissant assez de mémoire sur le système pour les autres processus. En bref, plus la taille du buffer pool s’approche de la taille des données+index, plus MySQL se comportera comme une base de données mémoire.
- Les logs InnoDB servent pour les opérations de recovery dans le cas d’un crash ou de transactions incomplètes. Comme nous l’avons vu au point 1, il y a deux fichiers de logs de 5M. Il est conseillé d’avoir une taille totale de log égale à 25% du buffer pool.
Enfin, MySQL Tuner nous fait un récapitulatif des recommandations.

Avant de modifier la configuration, assurez-vous:
– d’avoir fait une copie de votre fichier my.cnf
– d’avoir fait une sauvegarde de la base de données (via un dump par exemple)
Si vous êtes sur un environnement virtualisé, vous pouvez également faire un snapshot de la machine avant de démarrer la configuration du serveur.
Je vous conseille, pour chaque recommandation, d’aller vous informer dans la documentation MySQL afin de comprendre ce que vous modifiez.
Je vous conseille également de modifier la configuration petit à petit puis de laisser passer un peu de temps (et d’usages). Vous pourrez ensuite relancer l’analyse et réadapter en fonction du nouveau diagnostic.
La configuration d’un serveur MySQL se fait, en effet, en fonction des ressources disponibles mais également des usages (types de requêtes, fréquence, nombre de connections et d’utilisateurs, volume des données, …).
Si votre serveur n’est pas dédié à MySQL, ne négligez pas non plus les autres processus qui cohabitent sur le même système (apache, php, java, …) pour laisser de l’air à tout le monde.
Aller plus loin
Si vous souhaitez aller plus loin et comprendre les paramètres de configuration et de statuts, je vous conseille de vous référer, comme point de départ, à la documentation MySQL:
Commencez par dégrossir le travail en utilisant un outil comme MySQL Tuner qui établit déjà un premier diagnostic. Ne modifiez les paramètres (même lorsque cela est conseillé dans le diagnostic) qu’après avoir compris à quoi ils servent et si les nouvelles valeurs sont bien cohérentes avec le dimensionnement de votre serveur et son utilisation.
3. Analyse des requêtes longues
Activation des slow query logs
MySQL dispose d’une option de configuration qui permet de logger les requêtes longues pour permettre une analyse ultérieure. Pour activer ce log, modifiez la configuration ainsi:
[code lang= »bash »] slow_query_log_file = /var/log/mysql/mysql-slow.log slow_query_log = 1 long_query_time = 0 log_queries_not_using_indexes [/code]Les logs vont être inscrit dans le fichier mysql-slow.log. « long_query_time » indique le nombre de secondes à partir duquel on considère une requête comme longue. Ici, on a volontairement indiqué une valeur à 0 pour logger toutes les requêtes. Cela va, en effet, nous permettre d’analyser les temps de réponse de toutes les requêtes.
Dans une configuration standard, pour ne logger vraiment que les requêtes lentes, définissez ce paramètre à 1 ou 2.
Une fois, le slow query log activé, il faut attendre que MySQL log un échantillon représentatif des requêtes. Vous pouvez le laisser vivre sa vie en conditions réelles et normales d’utilisation si vous analysez votre serveur de production. Le mieux, si vous avez des scripts de tests (de votre application web par exemple), est de lancer des tirs de perfs à partir de ces scripts sur le serveur d’intégration.
Une fois le fichier mysql-slow.log alimenté, copiez-le et désactivé les slow query logs en commentant les lignes de la configuration précédemment modifiée.
Le fichier mysql-slow.log est difficilement utilisable en l’état car il contient une entrée par requête effectuée sur la base de données. Nous allons utiliser deux outils pour analyser ces données.
Recherche des requêtes longues avec mysqldumpslow
Le premier outil est une commande standard livrée avec MySQL: mysqldumpslow
[code lang= »bash »] mysqldumpslow -s at mysql-slow.log [/code] [code lang= »sql »] Count: 17 Time=673.44s (11448s) Lock=0.00s (0s) Rows=20.0 (340), root[root]@localhost SELECT w.name, COUNT( i.id), COUNT( f.id) FROM wishlist w LEFT JOIN item i ON i.wishlist=w.id LEFT JOIN friend f ON f.wishlist_id=w.id GROUP BY w.name LIMIT N,N Count: 1 Time=288.71s (288s) Lock=0.00s (0s) Rows=10.0 (10), root[root]@localhost SELECT w.name, COUNT(i.id), COUNT(f.id) FROM wishlist w LEFT JOIN item i ON i.wishlist=w.id LEFT JOIN friend f ON f.wishlist_id=w.id GROUP BY w.name LIMIT N Count: 1 Time=203.52s (203s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost UPDATE IGNORE item SET friend=FLOOR(N + (RAND() * N)) Count: 1 Time=75.80s (75s) Lock=0.00s (0s) Rows=956771.0 (956771), root[root]@localhost SELECT /*!N SQL_NO_CACHE */ * FROM `item` Count: 94 Time=57.99s (5451s) Lock=0.00s (0s) Rows=19.6 (1840), root[root]@localhost SELECT f.email, COUNT(i.id) FROM item i LEFT JOIN friend f ON f.id=i.friend GROUP BY f.id ORDER BY f.email LIMIT N,N Count: 1 Time=53.45s (53s) Lock=0.00s (0s) Rows=20.0 (20), root[root]@localhost SELECT u.name, w.name, f.email, COUNT(i.id) FROM item i LEFT JOIN friend f ON f.id=i.friend LEFT JOIN wishlist w ON w.id=i.wishlist LEFT JOIN user u ON u.id=w.owner_id GROUP BY u.name, w.name, f.email ORDER BY u.name LIMIT N,N Count: 1 Time=28.12s (28s) Lock=0.00s (0s) Rows=5566056.0 (5566056), root[root]@localhost SELECT /*!N SQL_NO_CACHE */ * FROM `friend` Count: 2 Time=12.27s (24s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost UPDATE item SET friend=FLOOR(N + (RAND() * N)) Count: 1 Time=8.78s (8s) Lock=0.00s (0s) Rows=2717.0 (2717), root[root]@localhost SELECT * FROM friend WHERE email LIKE ‘S’ … [/code]Cette commande regroupe toutes les requêtes similaires en ne prenant pas en compte les valeurs numériques et les chaînes de caractères. Avec l’option « -s at », les requêtes sont triées de celle ayant le temps moyen le plus long au temps moyen le plus court.
Avant de rentrer dans l’analyse des requêtes, regardons le deuxième outil.
Synthèse avec pt-query-digest
Le deuxième utilitaire est pt-query-digest de Percona.
Référez-vous à la documentation pour l’installer sur votre serveur. Sur Debian, procédez comme ci-dessous:
Lancez la commande suivante pour générer l’analyse:
[code lang= »plain »] pt-query-digest mysql-slow.log # Overall: 54.77k total, 130 unique, 1.72 QPS, 0.58x concurrency _________ # Time range: 2017-03-22 13:54:52 to 22:46:26 # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 18626s 1us 977s 340ms 26ms 12s 445us # Lock time 7s 0 190ms 125us 287us 2ms 76us # Rows sent 6.83M 0 5.31M 130.67 97.36 22.99k 0.99 # Rows examine 2.12G 0 93.98M 40.60k 9.80k 1.67M 0.99 # Query size 4.33M 0 493 82.83 441.81 105.63 36.69 # Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ================ ===== ======== ===== ========== # 1 0x538A90A8A873185A 11448.5396 61.5% 17 673.4435 47.98 SELECT wishlist item friend # 2 0x260404D96F652636 5451.3766 29.3% 94 57.9934 10.17 SELECT item friend # 3 0x181276D047E615F0 557.2783 3.0% 348 1.6014 0.28 SELECT wishlist item friend # 4 0xE414F9023BDD43A0 288.7140 1.6% 1 288.7140 0.00 SELECT wishlist item friend # MISC 0xMISC 879.6234 4.7% 54310 0.0162 0.0 <125 ITEMS> [/code]En synthèse, les résultats montrent que 95% des requêtes ont été effectuées en moins de 26ms avec tout de même un temps moyen par requête de 340ms. La requête la plus lente a durée 977s (soit ~16min).
La durée maximale durant laquelle une requête était en attente à cause d’un verrou sur une table n’a durée que 190ms.
pt-query-digest présente uns synthèse sur les 4 plus lentes requêtes, on voit, par exemple, que la requête n°1 a été appelée 17 fois et représente 61% des temps de réponse.
Dans la suite du rapport de pt-query-digest, vous avez le détail pour chacune des 4 requêtes les plus lentes.
Pour la requête n°3, par exemple, nous avons:
[code lang= »plain »] # Query 3: 0.04 QPS, 0.07x concurrency, ID 0x181276D047E615F0 at byte 9413566 # This item is included in the report because it matches –limit. # Scores: V/M = 0.28 # Time range: 2017-03-22 18:31:05 to 20:51:04 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 0 348 # Exec time 2 557s 19us 4s 2s 3s 666ms 2s # Lock time 0 54ms 0 1ms 155us 348us 108us 113us # Rows sent 0 6.67k 0 20 19.63 19.46 2.58 19.46 # Rows examine 3 81.57M 0 244.32k 240.01k 233.54k 30.41k 233.54k # Query size 1 60.83k 179 179 179 179 0 179 [/code]La même requête (en excluant les valeurs numériques et les chaînes de caractères) a été exécutée 348 fois. 95% des requêtes ont été exécutées en moins de 3 secondes pour une moyenne de 2 secondes. La durée maximale est de 4 secondes et la plus rapide de 19 micro-secondes (on peut supposer pour cette dernière l’utilisation du cache).
Les requêtes ont renvoyées en moyenne un peu plus de 19 lignes. Cependant le nombre de lignes examinées pour retourner le résultat est d’en moyenne 240 000.
La suite du rapport pour cette requête montre la répartition des temps de réponse.
[code lang= »plain »] # String: # Databases cdansmaliste # Hosts localhost # Users root # Query_time distribution # 1us # 10us # # 100us # 1ms # 10ms # 100ms ########### # 1s ################################################################ # 10s+ [/code]La majorité des temps de réponses se situent dans l’interval 1s-10s. Quelques réponses ont été effectuées en moins d’1 seconde. On voit également que les temps inférieurs à 1ms ne sont vraiment pas représentatif car trop anecdotiques.
Cette répartition est intéressante car elle pourrait également, dans certains cas, nous éviter de nous attarder sur une requête qui n’en vaudrait pas la peine. Par exemple, si on prend le cas d’une requête qui est globalement toujours très performante mais qui a un temps moyen d’exécution médiocre car elle a été, une seule fois, très lente en raison d’un gros traitement serveur qui a ralenti son exécution. Cette répartition mettrait en évidence le caractère « accidentel » de cette baisse de performance.
La dernière partie du rapport détaillé pour cette requête affiche une des requêtes SQL concernées (pour rappel, pt-query-digest regroupe les requêtes en supprimant les numériques par exemple 100 et 20 dans notre exemple).
[code lang= »plain »] # Tables # SHOW TABLE STATUS FROM `cdansmaliste` LIKE ‘wishlist’\G # SHOW CREATE TABLE `cdansmaliste`.`wishlist`\G # SHOW TABLE STATUS FROM `cdansmaliste` LIKE ‘item’\G # SHOW CREATE TABLE `cdansmaliste`.`item`\G # SHOW TABLE STATUS FROM `cdansmaliste` LIKE ‘friend’\G # SHOW CREATE TABLE `cdansmaliste`.`friend`\G # EXPLAIN /*!50100 PARTITIONS*/ SELECT w.name, COUNT(DISTINCT i.id), COUNT(DISTINCT f.id) FROM wishlist w LEFT JOIN item i ON i.wishlist=w.id LEFT JOIN friend f ON f.wishlist_id=w.id GROUP BY w.name LIMIT 100,20\G [/code]Ce travail d’analyse doit être fait sur les quelques requêtes détaillées par pt-query-digest.
Pourquoi passons nous d’abord par ces outils intermédiaires ?
Avant tout parce qu’il n’est pas possible de vérifier et d’analyser toutes les requêtes. Les deux outils vus plus haut nous permettent de repérer les requêtes les plus longues, d’identifier si elles sont ponctuelles et donc à ignorer (une requête de maintenance par exemple), ou si elles sont fréquentes.
Cette étape de cartographie des requêtes est primordiale car elle nous permet de comprendre les requêtes qui sont exécutées sur le serveur et d’identifier celles qui sont les plus lentes. Cela nous permet de focaliser l’étude qui va suivre sur des requêtes qui sont représentatives de l’utilisation qui est faite de la base.
Analyse des requêtes lentes
L’inventaire dressé par mysqldumpslow et pt-query-digest vous a normalement permis d’isoler quelques requêtes lentes représentatives pour réaliser l’examen qui va suivre.
Pour cet article, je me contenterais d’utiliser la requête n°2 précédente, il s’agissait d’une requête qui s’exécutait en moyenne en 58s. Demandons à MySQL son plan d’exécution en préfixant la requête du mot-clé « EXPLAIN »:
[code lang= »sql »] EXPLAIN SELECT f.email, COUNT(i.id) FROM item i LEFT JOIN friend f ON f.id=i.friend GROUP BY f.id ORDER BY f.email LIMIT 100 [/code] [code lang= »plain »] +—-+————-+——-+——–+—————+———————-+———+———————–+——–+———————————————-+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+——-+——–+—————+———————-+———+———————–+——–+———————————————-+ | 1 | SIMPLE | i | index | NULL | IDX_1F1B251E55EEAC61 | 5 | NULL | 991539 | Using index; Using temporary; Using filesort | | 1 | SIMPLE | f | eq_ref | PRIMARY | PRIMARY | 4 | cdansmaliste.i.friend | 1 | | +—-+————-+——-+——–+—————+———————-+———+———————–+——–+———————————————-+ … 100 rows in set (58.40 sec) [/code]On peut voir sur le plan que MySQL analyse 991 539 lignes en utilisant un index et que, pour faire cela, il prévoit d’utiliser une table temporaire qu’il la stockera sur disque pour faire le tri.
Il utilisera ensuite la clé primaire de friend pour la jointure.
Ici on peut l’aider de différentes manières.
Tout d’abord, au niveau de la conf, en modifiant le paramètre innodb_buffer_pool_size (cf plus haut) car nous voyons que nous manipulons beaucoup de données.
Deuxièmement, au niveau de la structure de la table, nous pouvons créer un index sur l’email car nous effectuons un tri sur ce champ.
Ensuite, nous pouvons optimiser la requête. En effet, on veut éviter que MySQL doivent analyser les 991M lignes… Pour cela on doit comprendre le modèle de données et ce que l’on cherche à faire avec cette requête.
Au niveau du modèle, pour faire simple, dans notre exemple: un et un seul « friend » est affecté à un « item », un « friend » peut donc avoir plusieurs « item », mais un « item » n’a qu’un « friend ».
Au niveau de la requête, on cherche à afficher le nombre d’items par friend le tout trié par l’email… pour ajouter de la complexité, on ne veut retourner que les 100 premiers résultats.
Nous pouvons trier et faire le limit avant de faire la jointure dans une sous-requête. Ce n’est pas vraiment académique, mais cela va permettre à MySQL de traiter moins de lignes au moment de la jointure.
[code lang= »sql »] EXPLAIN SELECT f.email, COUNT(i.id) FROM ( SELECT tf.* FROM friend tf ORDER BY tf.email LIMIT 100 ) f LEFT JOIN item i ON f.id=i.friend GROUP BY f.id; [/code] [code lang= »plain »] +—-+————-+————+——-+———————-+———————-+———+——+——+———————————+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +—-+————-+————+——-+———————-+———————-+———+——+——+———————————+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 100 | Using temporary; Using filesort | | 1 | PRIMARY | i | ref | IDX_1F1B251E55EEAC61 | IDX_1F1B251E55EEAC61 | 5 | f.id | 1 | Using index | | 2 | DERIVED | tf | index | NULL | IDX_friend_email | 767 | NULL | 100 | | +—-+————-+————+——-+———————-+———————-+———+——+——+———————————+ … 100 rows in set (0.00 sec) [/code]L’explain plan montre qu’il utilise le nouvel index sur la table de la sous-requête (3ème ligne). On observe qu’il n’utilise pas d’index et une table temporaire sur la requête principale, mais qu’il ne manipule désormais que 100 lignes, grace à la sous-requête (1ère ligne). Nous voyons ensuite qu’il utilise la clé primaire de friend pour faire la jointure (2ème ligne).
Le résultat de l’optimisation montre un temps de réponse < 10ms,… bien loin des 58s observées avant.
Il s’agit d’une partie du travail d’analyse qui est plus compliquée et qui n’est pas automatisable. Il va falloir regarder chaque requête, comprendre ce qu’elle fait et analyser l’explain plan car chaque cas est différent.
Pour cela, la doc MySQL est bien faîte et vous pouvez trouver toutes les informations pour comprendre le résultat d’un explain plan.
Activez le slow-query-log puis analysez le une fois qu’il aura été alimenté sur une période d’activité représentative d’utilisation.
Utilisez des outils comme mysqldumpslow et pt-query-digest pour obtenir une première lecture des logs et cibler votre analyse.
Analysez l’explain plan des requêtes qui ont les caractéristiques suivantes:
– souvent appelées (oubliez les requêtes liées à de la maintenance),
– lentes de manière habituelle (oubliez la requête qui a été lente 2 ou 3 fois à cause d’un pic de charge sur le serveur)
4. Analyse des usages
Une autre dimension de l’amélioration des performances consiste à s’intéresser aux usages qui sont fait de la base de données.
Les points suivants sont à analyser dans l’ordre de préférence ci-dessous.
Mesure de la pertinence des index
Vous pouvez tout d’abord analyser votre modèle de données et vos requêtes afin de déterminer si les index existants sont pertinents. Sont-ils vraiment utilisés ? Est-ce que leur construction est cohérente (ordre cohérent dans un index composé) ?
Recherche d’index manquants
Vous pouvez également rechercher des index manquant à l’appel sur certaines tables (index ou unique key).
Cela peut être le cas, par exemple si vous effectuez des WHERE, GROUP BY ou ORDER BY fréquemment sur des champs qui n’ont pas d’index.
De même pour les jointures, pour lesquelles les points de pivots doivent être définis comme clés étrangères.
Pour cela, vous devrez comprendre le modèle de données et l’usage qui est fait de la base soit par votre connaissance métier des applications qui utilisent la base soit en vous appuyant sur les requêtes types qui sont exécutées, comme nous avons pu le faire plus haut.
Ne créez pas non plus des index là où ce n’est pas nécessaire.
Les index consomment, en effet, plus d’espace disque et entrainent un surcoût sur l’exécution des requêtes d’écritures.
Type de champs
Cherchez à analyser les types de champs utilisés. Demandez-vous s’ils sont cohérents et s’il ne sont pas disproportionnés, c’est à dire si la taille allouée n’est pas trop grande (par exemple, utiliser un INT pour stocker une valeur allant de 1 à 10).
Utilisation du cache
Vous devriez considérer l’utilisation du cache, d’autant plus si vous observez des requêtes strictement identiques exécutées très fréquemment.
Pour voir si le cache est activé sur votre serveur:
Une fois le cache activé et utilisé pendant une période représentative, vous pouvez contrôler son efficacité ainsi:
[code lang= »plain »] SHOW STATUS LIKE ‘Qcache%’; +————————-+———-+ | Variable_name | Value | +————————-+———-+ | Qcache_free_blocks | 1 | | Qcache_free_memory | 12486496 | &amp;amp;lt;= !!! | Qcache_hits | 1528 | &amp;amp;lt;= !!! | Qcache_inserts | 515 | | Qcache_lowmem_prunes | 0 | &amp;amp;lt;= !!! | Qcache_not_cached | 111 | | Qcache_queries_in_cache | 386 | | Qcache_total_blocks | 777 | +————————-+———-+ [/code]On observe ici qu’il reste 12Mo d’espace libre dans le cache. Qu’il a renvoyé 1528 résultats et qu’il contient 386 requêtes.
L’autre variable intéressante est Qcache_lowmem_prunes qui indique si des requêtes ont été supprimées du cache pour laisser la place à de nouvelles. Si ce nombre est grand, vous devrez vous interroger: soit le cache n’est pas assez volumineux et il sera nécessaire de l’augmenter, soit le cache systématique n’est pas pertinent dans l’utilisation que vous faîtes de l’application (si vous avez beaucoup d’écritures).
Vous pouvez également mettre en place un cache au niveau de votre application (redis, memcached, …) si vous ne souhaitez pas utiliser le cache de MySQL.
Gestion des transactions
Afin de limiter les accès disques et augmenter le nombre de requêtes par seconde que peut traiter MySQL, essayez de regrouper les requêtes écritures dans des transactions en utilisant:
[code lang= »sql »] START TRANSACTION … COMMIT [/code]Visez une certaine cohérence fonctionnelle dans les regroupements, ne cherchez pas à tout regrouper systématiquement.
De même, vous devriez n’utiliser AUTOCOMMIT=1 que pour les transactions qui ne concernent que des lectures ou si vous n’effectuez qu’une seule modification en base de données.
Scaler verticalement
Si vous observez toujours des problèmes de performances après avoir exploré les autres étapes de cet article, cela peut être le signe qu’il faut scaler verticalement en augmentant les ressources RAM, CPU du serveur.
De même, si MySQL Tuner vous indique, suite à une augmentation d’un paramètre comme innodb_buffer_pool_size, que vous atteignez un niveau critique d’utilisation de la RAM du serveur.
Scaler horizontalement
Vous pouvez également scaler horizontalement (en multipliant les machines) et adapter ainsi l’architecture technique à votre usage.
Comme nous avons pu le voir plus haut, il y a 77% de lectures contre 23% d’écritures. La mise en place d’une réplication MASTER-SLAVE peut donc être intéressante. Le principe est d’avoir 1 serveur MASTER qui reçoit les requêtes d’écritures et n serveurs SLAVE qui reçoivent et traitent les requêtes de lecture.
La charge est ainsi répartie sur plusieurs serveurs.
Vous trouverez plus d’informations sur la configuration d’une réplication dans la documentation officiel.
L’inconvénient est que cela nécessite de modifier vos applications pour qu’elles redirigent les requêtes d’écritures sur le MASTER et les lectures « aléatoirement » sur les SLAVE.
L’optimisation de MySQL est également liée aux usages que vous en faîte. Cette dernière étape est plus fastidieuse car elle nécessite une bonne compréhension du modèle de données, de la volumétrie des données, des applications qui sollicitent la base et peut nécessiter une analyse unitaire des requêtes posant problème. Les étapes précédentes nous ont théoriquement permis de dégrossir le travail sur ce point et de concentrer nos efforts sur les points les plus pertinents en fonction de notre contexte.
Conclusion
Toutes les pistes n’ont bien sûr pas été explorées dans cet article et il reste difficile de généraliser car chaque cas est différent. Cependant, nous avons pu aborder, au cours de cet article, 4 étapes basiques permettant d’établir un premier diagnostic des performances de MySQL.
Comme vous avez pu le voir, l’amélioration des performances de MySQL est un sujet vaste qui touche aussi bien:
- la configuration du serveur,
- la structure des tables,
- le volume de données traitées,
- les requêtes qui sont exécutées
Tous ces aspects doivent être pris en compte dans la démarche d’audit des performances de MySQL et être adaptés en fonction de votre contexte.
Vous souhaitez vous faire accompagner
Nous réalisons des audits applicatifs qui incluent une partie diagnostic des performances de MySQL. Si vous voulez en savoir plus, cliquez sur le bouton ci-dessous…
Notre service d'audit applicatif